6 Best Pyannote Alternatives in 2026 (APIs, Open Source & No-Code)

Quick Summary
This guide explores the best pyannote alternatives for speaker diarization across APIs, open-source tools, and workflow-based platforms. It compares options like Cleanvoice, AssemblyAI, and Deepgram based on setup complexity, scalability, and production readiness.
Use it to choose the right fit for recorded audio, API integration, or automated content pipelines. For deeper audio workflow guides, explore the Cleanvoice blog.
Need a Simpler pyannote Alternative for Speaker Diarization Workflows?
If you’ve worked with pyannote.audio, you already know that the real challenge isn’t the diarization itself, it’s everything required to make it usable in production.
From GPU setup and HuggingFace authentication to building full transcription and cleanup pipelines, what starts as a simple audio task often turns into a heavy engineering workflow. For podcast teams, developers, and content creators, that overhead slows down delivery.
This Cleanvoice article explores the best pyannote alternatives, from managed APIs to all-in-one tools that combine diarization, transcription, and audio processing.
Why Listen to Us?
Cleanvoice processes voice recordings at scale, so we see where diarization tools work, break, and need extra cleanup. That experience helps us compare pyannote with managed alternatives built for cleaner speaker-labeled audio, transcripts, and production workflows.


What Is pyannote?

pyannote.audio is an open-source Python toolkit for speaker diarization built on PyTorch and accessible via HuggingFace Hub. It provides pre-trained models for speaker segmentation, embedding, and clustering. The current production model is pyannote/speaker-diarization-community-1 .
Key Features
- Pre-Trained Diarization Pipeline: Ready-to-use speaker diarization models are available through Hugging Face, so developers can test Pyannote without building a model from scratch.
- Modular Architecture: Pyannote separates the main diarization steps, making it easier to adjust parts of the workflow when more control is needed.
- Overlapping Speech Detection: Pyannote can detect when multiple people speak at once, which is useful for meetings, interviews, podcasts, and calls.
- Active Research Ecosystem: Pyannote is regularly updated with new models, benchmarks, and community improvements.
- Pretrained Model Checkpoints: Versioned checkpoints, including 3.1 and 4.0, make experiments easier to repeat and compare.
Pricing
Free and open-source core library.
Limitations of pyannote
- Complex setup requirements: Running pyannote typically requires GPU infrastructure and downloading large model files, making lightweight deployment difficult.
- No built-in transcription: It only provides speaker labels, so you need separate transcription tools to produce usable outputs.
- Accented & multilingual performance: Performance may degrade on accented or multilingual audio compared to domain-specific or commercial systems.
- Limited production guarantees: No SLA, no uptime guarantees, and version updates frequently break existing pipelines.
- Regression risks in 4.0: Open issues report a ~6x VRAM spike on the community-1 pipeline (9.54 GB vs 1.59 GB on 3.3.2) and unstable labels with over-segmentation on longer audio.
Best pyannote Alternatives
- Cleanvoice
- AssemblyAI
- Deepgram
- AWS Transcribe
- NVIDIA NeMo
- Speechmatics
Cleanvoice

Cleanvoice is a managed API for cleaning and preparing voice recordings. It approaches diarization differently from pyannote. Instead of returning raw speaker labels that still need extra tools, it gives you cleaner, speaker-labeled output from one workflow.
Upload a file, process it, and download the result. Cleanvoice handles speaker labels, noise cleanup, filler words, silence trimming, transcripts, and subtitles without a separate diarization stack.
Setup stays simple. Use the API for direct workflow control, or use the SDK to handle uploads, polling, and downloads with less custom code.
Cleanvoice is best for podcasts, interviews, and meetings that need clean, speaker-labeled audio without extra tooling. For real-time diarization, 10+ speakers, or raw model outputs, a developer-focused tool may be a better fit.
Key Features
- Studio Sound 3.0 Auto-Enhancement: Automatically improves voice clarity and removes noise across most workflows.
- Integrated Audio Editing Workflow: Combines diarization with noise removal, filler word detection, and silence trimming in a single pass.
- API and SDK access: Start with copy-paste-ready setup, then process files through the API or SDK with less custom code.
- Multilingual Support: Works across a wide range of languages and accents for global audio workflows.
- Speaker-Labeled Output: Produces speaker-attributed transcripts to simplify editing, search, and content reuse.
Pricing

Cleanvoice pricing starts with a free trial. No credit card required.
-
Pay-as-you-go credits:
- $11 for 5 hours ($2.20/hour)
-
Subscription plans:
- $11/month → 10 hours ($1.10/hour)
- $90/month → 100 hours ($0.90/hour)
-
Enterprise:
- 200+ hours/month
- Custom pricing
- Includes API access and business-specific requirements
Pros
- Cuts post-production from hours to minutes by eliminating manual cleaning and reassembly
- No GPU or model infrastructure to maintain
- No technical setup required, making it accessible for non-technical users and content teams
- Stronger multilingual accuracy than pyannote on non-English recordings
- Speeds up production for recurring podcast and interview workflows
Cons
- Not designed for real-time stream diarization
AssemblyAI

AssemblyAI is a speech AI API that treats diarization as a first-class feature alongside transcription, sentiment analysis, topic detection, and summarization. For developers embedding diarization in a product, it is the most complete managed alternative to pyannote.
Overlapping speech handling is better than most commercial APIs, though it remains below pyannote's research-grade performance on that specific metric.
Key Features
- Speaker-Labeled Transcription: Generates diarized transcripts in a single API call with no separate diarization step required.
- Built-in Audio Intelligence: Adds sentiment analysis, topic detection, auto-chapters, and summarization in one pipeline.
- Flexible Processing Modes: Supports both real-time and asynchronous transcription workflows.
- Unified API Endpoint: Combines transcription, diarization, and NLP features into a single developer-friendly endpoint.
- Webhook Support for Async Jobs: Allows event-driven workflows for large-scale or background audio processing.
Pricing

- Universal-2: $0.15/hour
- Universal-3 Pro: $0.21/hour
- Enterprise: Custom pricing for high volume and advanced rate limits
Note: Speaker diarization is included in Universal-2. Speaker Identification (named speakers) is a $0.02/hour add-on.
Pros
- Diarization and transcription delivered together, reducing integration complexity
- Well-documented API with SDKs across major languages
- Strong accuracy across speaker counts
- Easy to integrate into existing product workflows without ML expertise
Cons
- Costs scale significantly at high-volume audio processing
- Advanced NLP features perform best in English-only workflows
- Black-box model offers no visibility into diarization logic, less suited to research use cases requiring model inspection
Deepgram

Deepgram is a practical pyannote alternative for teams that need diarization inside a managed speech-to-text API. Instead of running pyannote locally and connecting it to a separate transcription tool, Deepgram returns transcripts with speaker labels through one API.
Its strengths are speed, simple setup, and API-based delivery, which makes it a good fit for podcasts, meetings, and call transcription at scale. Deepgram is less suited to teams that need open-source control, offline processing, or custom diarization pipelines.
Key Features
- Low-Latency Diarized Transcription: Delivers speaker-labeled transcripts in a single API call with minimal delay.
- Real-Time and Batch Modes: Supports both streaming transcription and asynchronous batch processing workflows.
- Batch Processing Mode: Handles asynchronous transcription for large audio files and datasets.
- Nova-3 Speech Model: Optimized for strong accuracy-speed balance across diverse and noisy real-world audio.
- Developer-Ready API: Simple integration for building transcription and voice intelligence features into applications.
Pricing

- Pay-As-You-Go: No minimum usage required
- Free Credits: $200 initial credit
- Growth Plan: Starts at $4,000+/year with prepaid credits and up to 20% savings
- Enterprise: Custom pricing with higher concurrency, expanded limits, and sales support
Pros
- Fastest processing speed among managed diarization APIs
- Competitive per-minute pricing for high-volume workloads
- Real-time streaming support for live applications
- Easy API integration for developers building voice features
Cons
- Speaker detection can be unreliable even in clean recordings
- Performance drops on non-English audio, especially with names and accents
- Some setups require WebSocket instead of HTTP, adding implementation complexity
AWS Transcribe

AWS Transcribe is Amazon's managed speech-to-text service with automatic speaker diarization supporting up to 30 speakers. For teams already operating in the AWS ecosystem, it is often the lowest-friction path to production diarization.
Organizations in regulated industries often use it because compliance features like HIPAA eligibility, SOC 2 alignment, and GDPR support are available out of the box.
This makes it particularly useful for enterprise teams that need documented security and data handling without building it themselves, something open-source setups like pyannote.audio cannot provide natively.
Key Features
- Speaker Diarization up to 30 Speakers: Built directly into the transcription pipeline.
- AWS Ecosystem Integration: Works natively with S3, Lambda, and other AWS services.
- Real-Time and Batch Processing: Supports both streaming and stored audio workflows.
- Enterprise Compliance Support: Includes HIPAA, SOC 2, and GDPR readiness.
- Scalable Cloud Infrastructure: Designed for high-volume, production-grade workloads.
Pricing
- Free Tier: Limited introductory usage for new accounts
- Pay-As-You-Go: Based on audio hours processed
- Enterprise Pricing: Custom quotes for large-scale or regulated workloads.
Pros
- Natural fit for teams already in the AWS ecosystem
- Enterprise compliance certifications without additional configuration
- Reliable for large-scale batch and streaming transcription workflows
- Scales easily for enterprise-level audio processing needs
Cons
- Accuracy on poor-quality or heavily accented audio lags behind specialist tools
- Less developer-friendly than Deepgram or AssemblyAI
- Costs can scale quickly without careful usage monitoring
NVIDIA NeMo

NeMo is NVIDIA's open-source speech AI and generative AI framework, and a more advanced technical alternative to pyannote for teams that want full control over their diarization pipeline. Its MSDD (Multi-Scale Diarization Decoder) architecture performs well on benchmark tasks, particularly in scenarios involving overlapping speech and variable-length recordings.
NVIDIA GPU hardware is effectively required for practical inference speed. It is the right choice for teams that need research-grade accuracy who can maintain ML infrastructure, not for those looking to reduce operational overhead.
Key Features
- Advanced diarization models: Supports MSDD and Sortformer for stronger handling of overlapping and multi-speaker audio.
- Combined ASR + Diarization Pipeline: Produces speaker-labeled transcripts within one framework.
- Open-Source Toolkit: Designed for customization and research-oriented workflows.
- Active NVIDIA Ecosystem Support: Regular updates tied to research and model improvements.
- Flexible Pipeline Design: Allows deep customization of audio pipelines.
Pricing

NVIDIA NeMo does not follow a fixed pricing model. It is accessed through NVIDIA AI Enterprise, cloud platforms, or self-hosted infrastructure. Costs vary depending on GPU usage and enterprise deployment setup.
Pros
- Benchmark accuracy exceeds pyannote on several standard DER evaluations
- Fully permissive Apache 2.0 license
- Combined ASR and diarization available in one framework, reducing integration points
- Suitable for teams needing fine-grained control over models and training
Cons
- Significant dependency footprint if diarization is the only required feature
- Requires NVIDIA GPU for practical inference speed
- Documentation is less focused than pyannote for diarization-specific implementation
Speechmatics

Speechmatics is a cloud speech-to-text API with built-in speaker diarization designed for production-grade transcription workflows. It is often used as a managed alternative to pyannote.audio in systems that need reliable speaker separation without managing models or infrastructure.
Speechmatics is chosen for its stability in real-world environments such as calls, meetings, and media transcription.
It handles diarization as part of a fully managed pipeline, making it easier to deploy compared to open-source setups that require GPU configuration and model management.
The tool is particularly useful for teams that need consistent performance across large volumes of multilingual audio.
Key Features
- Speaker diarization: Native multi-speaker labeling built into the transcription pipeline.
- Multilingual support: Strong performance across global accents and languages.
- Processing modes: Supports both real-time streaming and batch transcription.
- Managed API: No infrastructure or model hosting required.
- Scalability: Designed for high-volume, enterprise transcription workloads.
Pricing 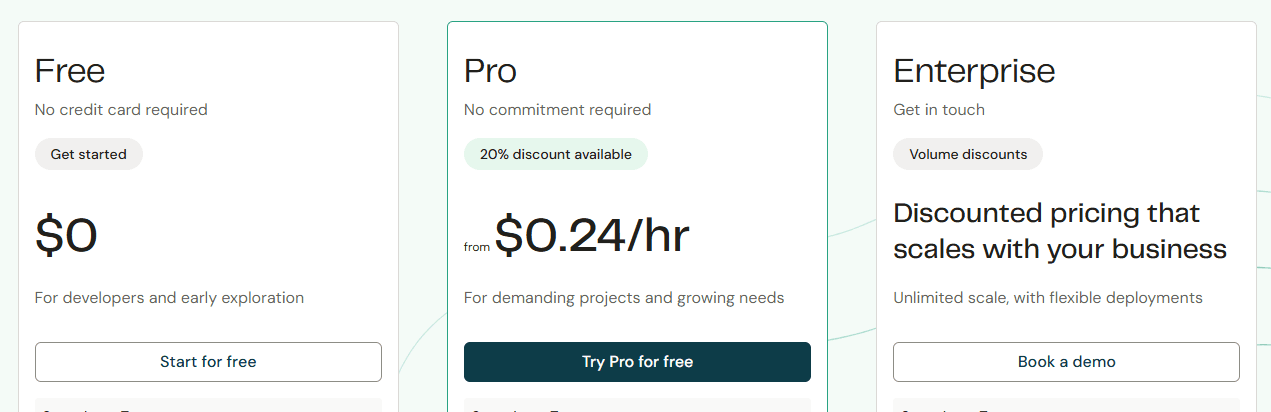
- Free Plan: 480 minutes/month, 2 concurrent real-time sessions, No credit card required
- Pro Plan: From $0.24/hour
- Enterprise Plan: Custom pricing
Pros
- Reliable diarization performance in production environments
- Strong performance in multilingual and accented speech environments, including code-switching scenarios
- Easy to deploy without ML infrastructure or GPU setup
- Consistent results across different audio qualities and recording conditions
Cons
- Limited flexibility for custom ML pipeline control
- Fewer speech intelligence features than API-first alternatives like AssemblyAI
- Less developer ecosystem compared to larger platforms like AWS
Get Production-Ready Speaker Labels with Cleanvoice
pyannote is widely used for research-grade diarization, while tools like AssemblyAI, Deepgram, AWS Transcribe, and Speechmatics provide managed APIs for scalable transcription workflows. Each option serves different technical needs depending on setup, control, and integration requirements.
Cleanvoice takes a different approach. It gives you cleaner, speaker-labeled audio without GPU setup, HuggingFace tokens, or separate transcription tools. Use the API for direct control, or start faster with the SDK, copy-paste setup, and less custom code.
Sign up for free and process your first recording in minutes.


